|
I am a Research Scientist at Allen Institute for AI. I work on the Aristo project. My research focuses on Interactive Agents, Machine Reasoning, Scientific Discovery, User-centric ML, and Social Science. I received my Ph.D. in Computer Science from UC San Diego, advised by Julian McAuley. I was fortunate to receive UCSD CSE Doctoral Award for Excellence in Research (2022), Adobe Research Fellowship (2022), Qualcomm Innovation Fellowship (2020), and
led UCSD (Team Bernard) in Amazon Alexa Prize, 2019. |

|
| Previously, I spent wonderful summers at Allen Institute for AI, Facebook AI Research, Microsoft Research, and Google AI Research. I worked as a technical editor for The Batch, a weekly newsletter by deeplearning.ai. I also co-authored a best-selling book on NLP with O'Reilly Media. |
| Research · Awards · Book · Talks · Experiences · Education |
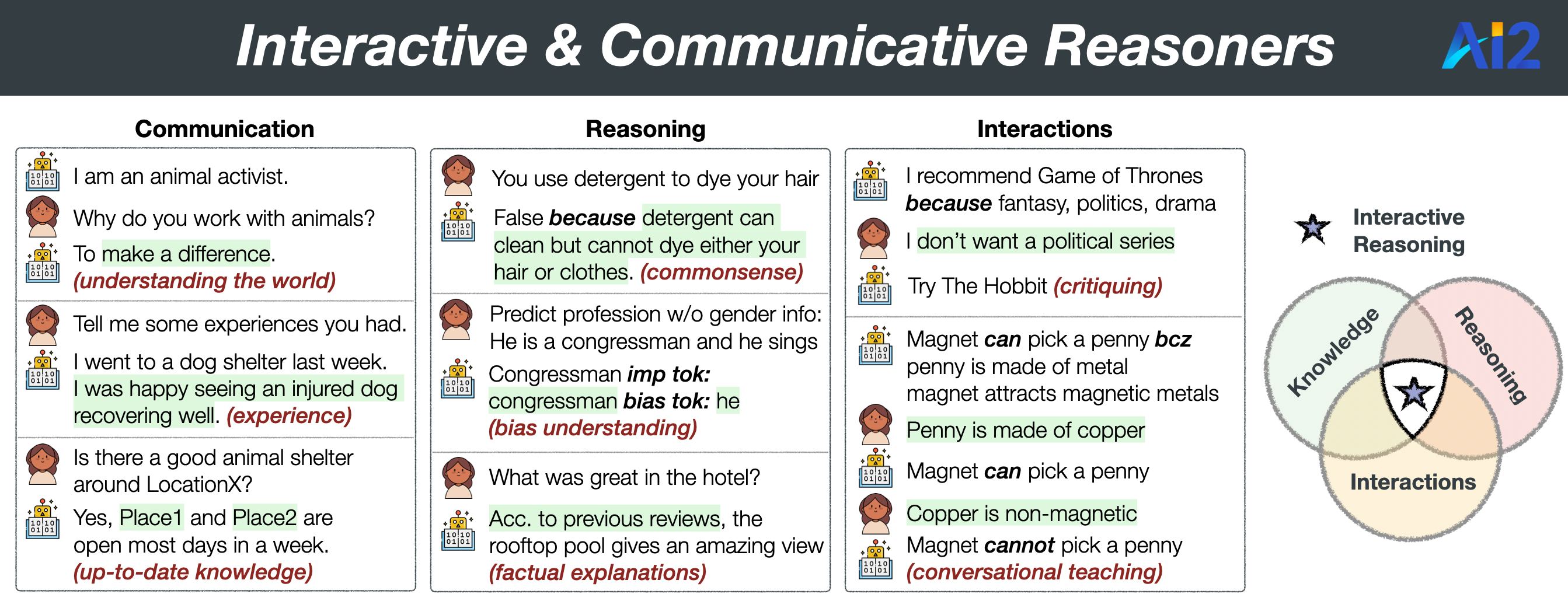
Machine understanding often suffers from the lack of reasoning with world knowledge, making them less reliable and potentially risky. My research goal is to develop communicative reasoners that can learn, adapt, and reason by interacting with the world and produce effective, explainable, and equitable outcomes.
|
(scroll for more)
- [Sep] Invited Talk at Semantic Machines on Automated Discovery with Communicative Agents.
- [Aug] Keynote at the Wordplay: Where Language meets Games workshop, ACL 2024 on Automated Discovery with Communicative Agents.
- [Jul] Invited talk at University of California, San Diego on Continual Learning with Language Agents.
- [Mar] Invited talk at University of British Columbia on Continual Learning with Language Agents.
- [Mar] Invited talk at University of Pennsylvania on Continual Learning with Language Agents.
- [June] I joined Allen Institute for AI (team Aristo) as a Research Scientist. 🔬
- [May] I successfully defended my PhD thsis!! 🎓 Access my defense talk here.
- [May] Paper w/ Oxford collaborators on natural language explanation consistency got in ACL 2023.
- [April] New work on Self-Refining LLMs w/ collaborators from AI2, CMU, Google, UW, and NVIDIA.
- [Mar] Proposal on Persona-grounded Dialog Generation received Sony Research Award.
- [Feb] Served as a Session Chair for Language Generation and Conversational AI tracks at AAAI, 2023.
- [Nov] Paper w/ Zhouhang, Sammer, and Julian on factual explanations got in AAAI, 2023.
- [Nov] Our RecSys paper got recognized as Hightlights of ACM Recsys '22.
- [Nov] Upcoming talk at Harvard University and Harvard Business School. Thanks Hima!
- [Nov] Upcoming talk at University of Southern California and USC-ISI. Thanks Xiang!
- [Nov] Upcoming talk at University College London. Thanks Oana!
- [Oct] Upcoming talk at University of California, Irvine. Thanks Sameer!
- [Oct] Upcoming talk at University of British Columbia. Thanks Vered!
- [Jul] Delighted to receive TrustNLP travel grant for NAACL 2022 and volunteer award for ICML 2022!
- [Jun] Paper w/ Shuyang and Julian on conversational rationale critquing in recsys got in ACM RecSys, 2022.
- [Jun] Honored to receive the Docotral Award for Excellence in Research from CSE, UC San Diego, 2022!
- [May] Traveling to Dublin at ACL 2022 for an oral presentation of our dialog paper. Come, say hi!
- [May] Paper w/ Oana, Thomas, and Julian on natural language explanations got in ICML, 2022.
- [Mar] Glad to be featured in CSE news by UC San Diego, for my Adobe Research Fellowship!
- [Feb] Paper w/ Harsh, Taylor, and Julian on unsupervised knowledge injection in dialog got in ACL (main), 2022.
- [Jan] Excited to join as a techincal editor for The Batch, a weekly newsletter by deeplearning.ai.
- [Jan] I am fortunate to be named as an Adobe Research Fellow 2022!
- [Jan] Joining Allen Institute for AI (AI2) in Summer 2022 to work with Peter Clark on interactive explanations.
- [Nov] Delighted to co-organize two workshops at ACL, 2022! Follow the spaces for more:
Representation Learning for NLP and Commonsense Reasoning and Representation. - [Nov] Invited talk (tweet) at AI2 on Producing Explanations with Commonsense and Interactions.
- [Aug] Paper w/ Zexue and Julian on debiasing sensitive texts got accepted in Findings of EMNLP, 2021.
- [Aug] Proposed my thesis on Language Generation with Interactions, Explanations, and Commonsense.
- [Jul] Invited talk on Explainable Language Generation with Commonsense at Facebook AI Research.
- [Jul] Invited talk on Explaining ML models with Commonsense at Oxford ML group, University of Oxford.
- [Jun] New work on Language Explanations for ML models with Commonsense w/ Oana, Thomas, and Julian.
- [May] Paper Rezero on making deeper networks faster got accepted in Uncertainty in AI (UAI), 2021
- [May] Honored to receive Friends of the International Center Fellowship, 2021 from UC San Diego.
- [May] Paper w/ Harsh, Taylor, and Julian on enriching dialog with background stories got accepted in ACL, 2021.
- [Mar] Work at Microsoft Research got accepted as a long paper in NAACL, 2021 w/ Sudha, Michel, and Julian.
- [Mar] Invited talks on Grounding Language Generation with World Knowledge at Microsoft Research, IIT Kharagpur.
- [Mar] Invited talks on Clarification Question Generation with Global Knowledge at Microsoft Research, UC San Diego.
- [Feb] Excited to be featured by Jacobs School of Engineering, UC San Diego, for our QIF Fellowship!
- [Jan] Launched GEM Benchmark (shared task in ACL, 2021) for evaluation in Natural Language Generation tasks!
- [Jan] We are organizing SoCal ML & NLP symposium 2021 virtually! Please consider submitting by Feb 16, 2021.
- [Jan] Joining Facebook AI Research for Summer 2021 to work with Y-Lan Boureau on Language Generation.
- [Oct] Invited talk on Achieving Commonsense in Text Generation at NC State. See slides here.
- [Sep] Two long papers (#1, #2) w/ Harsh, Taylor, Shuyang, Jianmo, and Julian got accepted in EMNLP (main), 2020.
- [Aug] Received Qualcomm Innovation Fellowship 2020 for our proposal on Conversational Recommender Systems.
- [Jul] Our book Practical Natural Language Processing has become #1 best seller in Amazon! Know more here.
- [Jun] Excited that my internship work at Google got featured in the Google AI blog! Check out for more.
- [April] Work at Google AI got accepted in ACL, 2020 as a long paper w/ Navneet, Sandeep, James, Qi and Marc.
- [Mar] New work on making deeper networks faster (ReZero) w/ Thomas, Henry, Gary and Julian.
- [Feb] Organizing SoCal Machine Learning Symposium, 2020 w/ Julian, Jingbo and Hao at UC San Diego.
- [Jan] Invited talk on Personalized NLG in the AI/ML track at CSE Research Open House, UC San Diego.
- [Nov] Joining NLP Group @ Microsoft Research for Summer 2020 to work on Natural Language Generation.
- [Sep] 'Intern Spotlight' in Google-wide Newsletter for work on Generalization in Document Understanding.
- [Aug] Two papers (#1, #2) w/ Shuyang, Henry, Gary and Julian got accepted in EMNLP, 2019.
- [Jun] Leading UC San Diego (Team Bernard) in the finals of Amazon Alexa Prize 2019. Media coverage on cnet.
- [Feb] Co-authoring a book titled 'Practical Natural Language Processing' with O'Reilly Media.
- [Jan] Joining Google AI Research for Summer 2019 to research on Generalized Information Extraction.
The complete list of publications can be seen from my Google Scholar page. Some works are highlighted.
(* denotes equal contribution)
|
The first data-driven discovery benchmark containing 264 tasks collected across 6 diverse domains, such as sociology and engineering, with manually derived discovery workflows from published papers to approximate the real-world challenges faced by researchers. |
|
Instruct-LF, a goal-oriented latent factor discovery system that integrates LLM's instruction-following ability with statistical models to handle large, noisy datasets where LLM reasoning alone falls short. |
|
The first virtual environment for developing and benchmarking an agent's ability to perform end-to-end novel discovery. |
|
A novel non-parametric continual learning paradigm for rapid adaptation and generalization to unseen tasks and environments for language agents. We show a dynamic, persistent, semantic memory centered around causal abstractions significantly amplifies transfer and learning without any additional parameter update. |
|
A framework capable of learning and applying conversation strategies in the form of natural language inductive rules from expert demonstrations. |
|
A simple architecture with two LLM agents used sequentially, one that edits a generic how-to procedure and one that verifies its executability, performs best in customising plans and procedural texts. |
|
A practical first step toward an end-to-end automation for scientific discovery. We posit that Large Generative Models (LGMs) present an incredible potential for automating hypothesis discovery, however, LGMs alone are not enough. |
|
Skill Set Optimization improves LLM actors through constructing and refining sets of transferable skills. Leveraging environment reward signals, generalizable skills enable significant continual improvement for frozen LLM actors. |
|
A novel framework that utilizes readily available or easily acquired text descriptions to guide robust transfer of discriminative knowledge from labeled source to unlabeled target data with domain gaps. |
|
A conversational critiquing framework to provide feedback on rationales behind a recommendation and iteratively update underlying recommendation model for faster convergence to target predictions. |
|
We show there exists algorithmic predictors that can detect novel but accurate language cues in many cases where humans failed to detect deception, opening up the possibility of human-AI collaboration in ameliorating human's ability to detect lies. |
|
Fairness in debiasing (i.e., balancing task performance and bias mitigation) is subjective and difficult to learn from data. In an interactive setup, we enable users to provide feedback and achieve a better balance, supported by controllable explanations. |
|
We discover that, in addition to the typical approach of prompting LLMs with demographics and ideology for personalization, utilizing the most relevant past opinions from individual users enables the model to predict user opinions more accurately. |
|
Empirical evidence on a broad array of tasks incites promising research direction: LLMs can auto-heal for better outcomes without any supervised training, or RL, or human feedback. |
|
The largest-scale data (till date) for conversational recommendation systems, discovering new trends for context sensitivity when LLMs are used as recommenders. |
|
An adversarial framework shows even high-quality natural language explanation do not have necessarily low-level of inconsistencies. A remedy method is proposed that shows additional knowledge-grounding improves robustness. |
|
A personalized self-rationalizing retrieve-generate framework for factually grounded reviews to explain rating and recommendation predictions with high attribution towards past reviews and informaitve keywords. |
|
Current debiasing models may over-debias. With local explanations and interventional training, we establish the fair balance between debiasing and predictability for several classification and generation tasks. |
|
A conversational critiquing framework to provide feedback on rationales behind a recommendation and iteratively update underlying recommendation model for faster convergence to target predictions. |
|
A unified framework to map extractive rationales and abstractive natural language explanations (NLE) of ML Models using commonsense. We establish new state-of-the-art in NLE generation, rationale extraction and predictive task performance. |
|
A post-hoc knowledge-injection technique that first retrieves and selects a diverse set of relevant knowledge snippets and further inject them into an initial response from an exisiting dialog model. Enriching dialog responses at decoding time with external knowledge (without re-training the existing models) promotes achieving conversational goals. |
|
A rewriting framework that first detects sensitive components from input text and then perturbs the generation model at decoding time under a neutralizing constraint. No parallel corpus of sensitive-neutral texts is needed for training. |
|
A novel deep neural network architecture that initializes an arbitrary layer as the identity map (ReZero), using a single additional learned parameter per layer to facilitate very deep signal propagation. |
|
An unsupervised gradient-based rewriting framework to adapt potential background stories to an existing persona-grounded dialog. We constrain the generation for self-consistency with persona and promote its adherence to the story. |
|
GEM is a community-driven effort with the goal to improve how progress in natural language generation is measured. As a shared task in ACL 2021, we invite for challenge set submissions for 11 datasets and 7 languages in various NLG challenges. |
|
A two-stage framework that 1) estimates missing information from the global knowledge of similar contexts, and 2) conditionally generates useful questions using gradient-based decoding based on a usefulness scorer at the inference time. This work was done during an internship at Microsoft Research. |
|
A variational learning framework to capture commonsense implications of input persona in a persona-grounded dialog agent using richer expansions obtained from existing commonsense knowledge bases. |
|
The first large-scale analysis of discourse in media dialog ("Interview" - 105K conversations) and its impact on generative modeling of dialog turns, with a focus on interrogative patterns and use of external knowledge. |
|
A framework for an engaging open-domain socialbot with a stateful autonomous dialog manager using non-deterministic finite automata to control multi-turn conversations. This work was done for Alexa Prize 2019. |
|
A novel approach to learn interpretable representations for target fields using spatial and contextual knowledge for extracting structured information from form-like document images, even with unseen templates. This work was done at Google AI as a part of 2019 summer internship. |
|
Media coverage: Science Node, UCSD CSE News, UCSD JSOE News A new task of personalized recipe generation to help these users: expanding a name and incomplete ingredient details into complete natural-text instructions aligned with the user's historical preferences. |
|
A multi-task learning scheme to achieve quantitatively better common sense reasoning in language models by leveraging auxiliary training signals from datasets designed to provide common sense grounding. |
|
A state-of-the-art approach towards post-OCR text correction for digitising texts in Romanised Sanskrit. This work was done in a collaboration with CNeRG. |
|
A non-parametric Bayesian approach for learning (Probabilistic) Context Free Grammar productions for Sanskrit language at word-level supervised tasks such as compound type identification, identification of source and derived words from the corpora for derivational nouns and sentence-level structured prediction. This work was done at CNeRG. |
|
We demonstrate the potential of neural recurrent structures in product attribute extraction by improving overall F1 scores, as compared to the previous benchmarks. This has made Walmart e-commerce achieve a significant coverage of important facets or attributes of products. This work from Walmart Labs later followed by a US patent. |
|
We processed 18 million transactions consisting of unique 325,548 products from 1,551 categories to obtain vector representations which preserve product analogy. These representations were effective in identifying substitutes and complements. This work was done at Walmart Labs. |
|
How similar are the dynamics of meme based communities to that of text based communities? We try to explain the community dynamics by categorising each day based on temporal variations in the user engagement. Work done at CNeRG. |
|
|
|
|

|
Practical Natural Language Processing
distills our collective wisdom on building real world applications such as data collection, working with noisy data and signals, incremental development of solutions, and issues involved in deploying the solutions as a part of a larger application - bridging a gap between current textbooks and online offerings.
|
|
|
|
|

|
Devloping communicative and interactive language agents. |

|
Devloping personalized, commonsensical, and empathetic dialog systems. |

|
Developed a novel framework that estimates missing 'local' information from the knowledge of a closed-world to generate a useful clarification question. Our work got accepted as a long paper in NAACL '21. |

|
Building free-form social conversational agent as a finalist in the Amazon Alexa Prize Challenge 2019-20 along with 9 other finalist universities. We were awarded $250,000 to research on dialog systems. |

|
Developed an Information Extraction Framework for form-like documents using representation learning. The work was published as an Intern spotlight article in the Google-wide Newsletter and is being integrated with Google Cloud's Document AI. Our work got accepted as a long paper in ACL '20. |

|
Developed a neural multimodal attribute tagging framework to improve faceted product using both product description and product images. The work produced 2 US patents and one technical report published in arXiv. Other works on user modeling and product embeddings also have been patented. |
|
|
|
|

|
Thesis: User-centric Natural Language Processing |
|
|
CGPA: 4.0; Courses: Intro to NLP, Data Mining, Program Synthesis, Deep Learning for Sequences, Probabilistic Reasoning, Intro to Computer Vision, Convex Optimization, Human-centered Programming |

|
Summa cum laude (Gold Medalist); Advised by Prof. Animesh Mukherjee as a part of CNeRG lab. Courses: Algorithms, Intro to ML, Multivariate Analysis, Complex Networks, Information Retrieval |
|
Thanks to Jon Barron for this nice template! |